| Per la stesura di questo articolo, gli autori si sono avvalsi dell’assistenza di risorse di IA generativa indipendenti. |
C’è chi si ostina olisticamente a usare la formulazione “intelligenza artificiale”, nebulosa metafora dispensatrice di marketing e sensazionalismo. Il limite di questo approccio è evidente nel fatto che è andata persa la qualifica “generativa”: una caratteristica distintiva, che indica la capacità di una sottoclasse dei sistemi di AI di generare – appunto – esiti plausibilmente attribuibili a esseri umani.
Andando oltre le definizioni e adottando un approccio analitico, si comprende che i dispositivi in gioco sono molti, che sono riconducibili da un punto di vista generale alla modalità appena descritta, ma anche che hanno varie particolarità che possono modificare l’infrastruttura sottesa, le condizioni da essa determinate, il contesto operativo e i comportamenti, le aspettative e la progettazione degli utenti.
Vogliamo perciò informare i lettori su una possibilità poco nota: attivare servizi generativi che funzionano in modo completo sfruttando risorse software autosufficienti, ospitate esclusivamente sui computer in possesso di chi le impiega: in poche parole girano interamente sul proprio computer, senza dipendere da server esterni.
Internet interviene soltanto per installazione e aggiornamenti, per il resto non è necessaria. E garantisce un buon livello di privacy. Tutti i dati, infatti, saranno inseriti, elaborati, prodotti e archiviati sull’hardware “locale”, quello posato su tavoli e scrivanie.
Schema generale di funzionamento
Chi ha utilizzato sistemi di conversazione basati su IA generativa (dal capostipite ChatGPT, a Gemini, a Claude, fino a Deepseek e a Qwen, i concorrenti cinesi che qualche tempo fa hanno avuto effetto anche in borsa, e così via) si è probabilmente costruito uno schema interpretativo di questo tipo:

In realtà il sistema di relazione è nettamente più articolato, una sorta di scomposizione della precedente rappresentazione grafica:
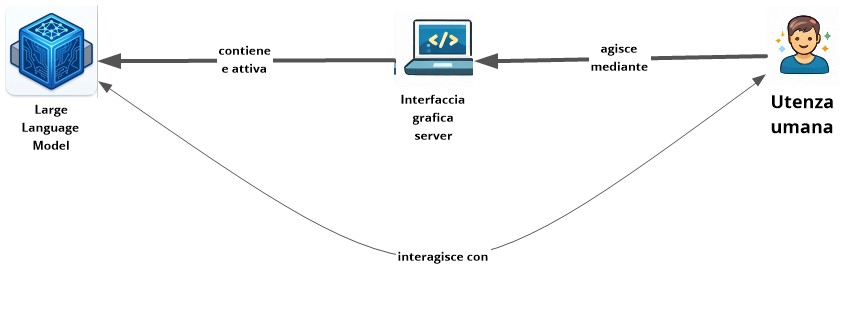
L’immagine rappresenta il “viaggio” che compie un’informazione quando usiamo un modulo operativo complesso di Intelligenza Artificiale Generativa, diviso in tre parti principali:
- l’utente ha un bisogno o una domanda che inserisce nel sistema mediante l’interfaccia, ovvero l’insieme di spazi di scrittura, menu e pulsanti che gli consentono di inoltrare un comando espresso in linguaggio naturale, che viene chiamato prompt, avviando la conseguente elaborazione;
- l’utente è davanti a un sito web o a un’applicazione per smartphone che hanno il ruolo di intermediari: ricevono il prompt e lo inviano al software che ha il compito di elaborare la risposta. Il server, che ospita il Large Language Model, addestrato su quantità enormi di dati, analizza il prompt tramite il modello, costruendo e restituendo una risposta all’utente.
L’utente agisce sul proprio dispositivo, interfaccia e LLM sono sul cloud, ovvero “in remoto”.
Quando il processo avviene invece “in locale”, la logica di funzionamento (input → elaborazione → output) rimane analoga, ma sia l’interfaccia server sia il Large Language Model sono sul dispositivo dell’utente, che deve disporre di sufficiente RAM[1] per caricare il modello senza compromettere le prestazioni del sistema. Stiamo parlando di Ollama (un runtime[2] locale per eseguire LLM), o di interfacce grafiche come LM Studio, Jan, GPT4All, AnythingLLM, che permettono di caricare e interrogare modelli linguistici[3]. Sono invece LLM scaricabili sul proprio PC personal computer Llama, Mistral, Gemma, DeepSeek, Qwen, tutti in varie versioni, e moltissimi altri[4]. In questo contributo utilizziamo a titolo esemplificativo Ollama.
Emancipazione e consapevolezza
A partire dal novembre 2022, quando ChatGPT ha invaso lo spazio operativo e cognitivo dei dispositivi digitali, la gran parte degli utenti si è adagiata in analoghe soluzioni “chiavi in mano”, i pacchetti via via confezionati dall’industria culturale dei giganti del web. Noi siamo convinti che affiancare – se non sostituire – queste pratiche con l’IA generativa in locale possa avere un valore emancipante per adulti e giovani, per insegnanti e studenti. E non solo e non tanto perché risolve in larga misura la questione della riservatezza e aiuta nella difesa dei dati, ma perché non propone il consumo di servizi semi-standardizzati (che promettono efficienza, ma chiedono in cambio una riduzione della nostra autonomia).
Ciò che cerchiamo è in primo luogo l’acquisizione di pratiche emancipanti. Per noi, infatti, l’IA non è un servizio da consumare passivamente, ma un dispositivo da abitare, smontare, studiare e governare. Eseguire un modello linguistico (LLM) senza passare per i server proprietari di internet vuol dire, tra l’altro, uscire dal recinto dei centri di potere oligopolistico, a livello individuale ma anche collettivo.
In secondo luogo, questa pratica alternativa apre la strada alla comprensione, da parte di tutti gli utenti-cittadini coinvolti, che i pensieri – o meglio, i dati che li rappresentano – non devono percorrere migliaia di chilometri per essere confermati o migliorati da frotte di misteriose scatole chiuse che simulano conversazioni. I dispositivi digitali in loro possesso si configurano infatti come autonomi banchi di lavoro vivo, spazi artigianali aperti e sostenibili dove agire intenzionalmente in modo auto-controllato, critico, etico e consapevole.
La bottega digitale in azione
Gli insegnanti sono il riferimento artigianale di studenti-apprendisti. Lo scopo di tutti è incrementare le capacità di comprensione e comunicazione del gruppo. L’uso di servizi generativi governati in locale comporta infatti:
- allestimento iniziale e progressiva ottimizzazione dei dispositivi in uso;
- un sempre più raffinato orientamento logico-linguistico degli ambienti di lavoro: i system prompt, istruzioni specifiche che possono indirizzare i processi di elaborazione verso obiettivi ben definiti. Questo corredo va quindi costruito, manutenuto e aggiornato con grande cura, mediante dialogo nel gruppo di lavoro;
- condivisione e discussione critica delle diverse tipologie di istruzioni, che sono considerate by design come patrimonio collettivo – bene comune – e non come capacità individuale da mercificare;
- progettazione e realizzazione di applicazioni sulla base di individuazione di bisogni e necessità del gruppo e dialogo con il dispositivo, che è in grado di sostenere (in prima istanza o come assistente) la scrittura di codice, a sua volta bene comune del gruppo;
- costruzione, co-costruzione ed eventuale decostruzione di basi di conoscenza contestualizzate e condivisibili, che utilizzano con cura e attenzione la risorsa RAG (Retrieval-Augmented Generation), una funzione avanzata dei modelli di linguaggio che combina l’architettura di ricerca con quella generativa, consentendo agli utenti di selezionare e raccogliere informazioni specifiche in pacchetti qualificati, su cui poi compiere ricerche.
- risposta del dispositivo a richieste di elaborazione di applicativi esterni, ad esempio le estensioni di LibreOffice che arricchiscono gli applicativi di risorse generative locali, in particolare per l’assistenza alla scrittura di testi.
Ci muoviamo sulla base di una prospettiva generale: attrezzi e manufatti digitali non devono sostituire il pensare umano, ma ridurre il carico cognitivo superfluo e la fatica esecutiva quando questa sia diventata meccanica e ripetitiva o priva di significatività formativa.
Questo approccio ha due implicazioni di lungo respiro. Non è sensato definire a priori percorsi didattici vincolati e vincolanti, e ha poco senso riferirsi a framework statici e quindi illusori.
Inoltre, poiché a decretare il successo di un laboratorio artigianale non è la metrica della produttività della macchina, ma quella dell’utilità, della coerenza e della congruenza di attività con necessità, il possibile rallentamento delle elaborazioni locali non è un difetto, ma un valore aggiunto, perché fornisce il tempo per una serena definizione e per una dialogica discussione di obiettivi, aspettative, valutazione degli esiti, perfezionamento delle istruzioni e così via.
Schede
Guida all’installazione e configurazione di Ollama
Ollama è lo standard per l’IA locale. Nasconde i dettagli tecnici. A differenza di altri programmi, non devi scaricare file grandi a mano o impostare driver difficili. Fa quasi tutto da solo.
Installazione sui vari sistemi
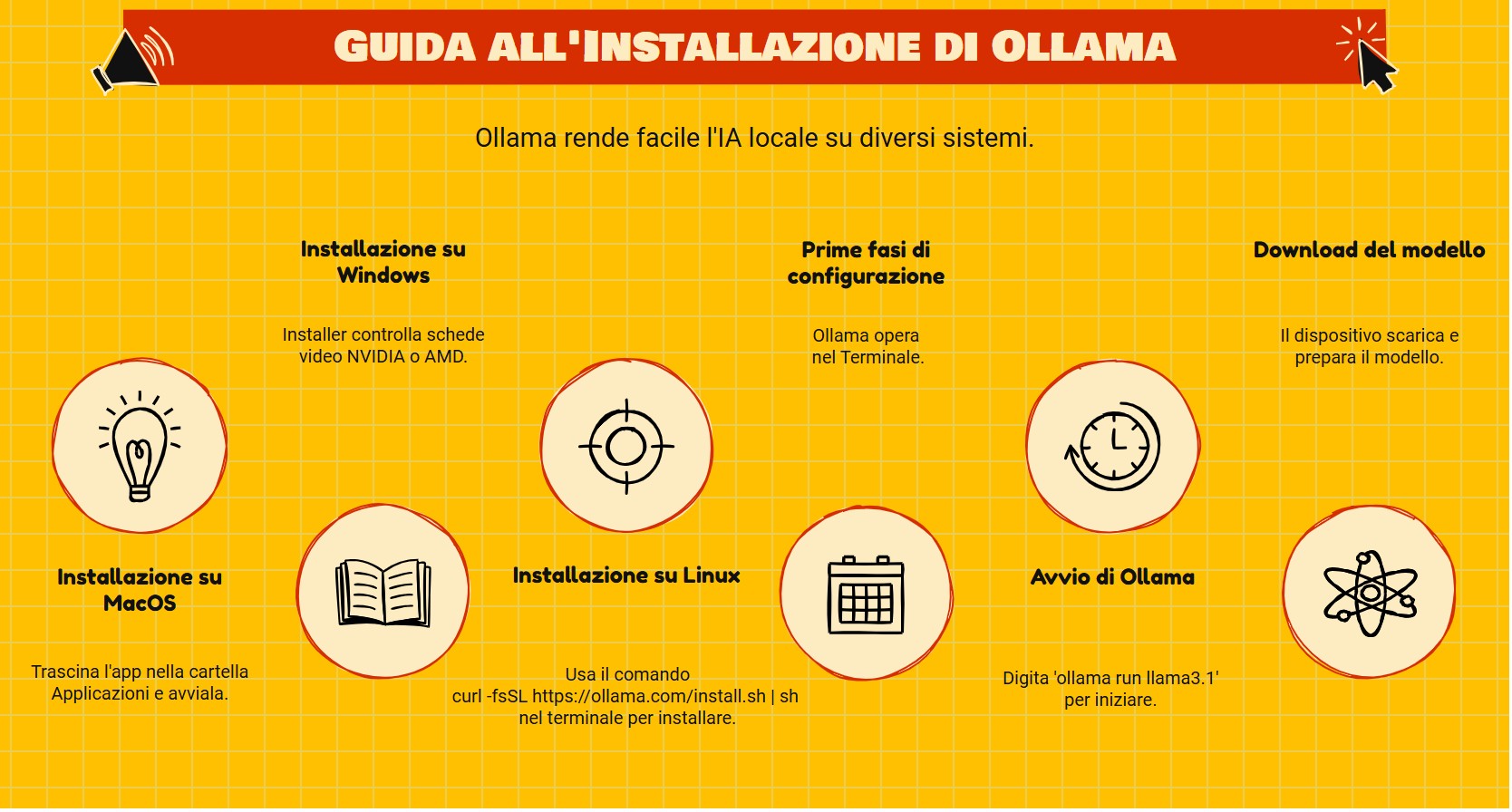
MacOS: Qui Ollama funziona al meglio. Scarichi un file .zip, trascini l’app nella cartella Applicazioni e la avvii. Il Mac usa subito la RAM unificata e regola il processore (Apple Silicon o Intel).
Windows: Dopo molti test, la versione per Windows è stabile. L’installer controlla se hai schede video NVIDIA o AMD. Una volta installato, Ollama appare nella barra di sistema (vicino all’orologio) e aspetta i comandi.
Linux: Lo installi con un solo comando nel terminale (curl -fsSL https://ollama.com/install.sh | sh). È l’opzione per chi vuole usare un vecchio PC come server per l’IA.
Configurazione e primo avvio
Ollama non ha un’interfaccia grafica di base. Lavora nel Terminale (o Prompt dei comandi).
Apri il terminale.
Scrivi ollama run llama3.1 (o il nome del modello che vuoi).
Il dispositivo scarica il modello e, finito il download, è pronto per chattare.
Se vuoi un’interfaccia come ChatGPT, collega Ollama a tool esterni come Open WebUI o Page Assist.
Criteri di scelta degli LLM: decodificare i nomi tecnici
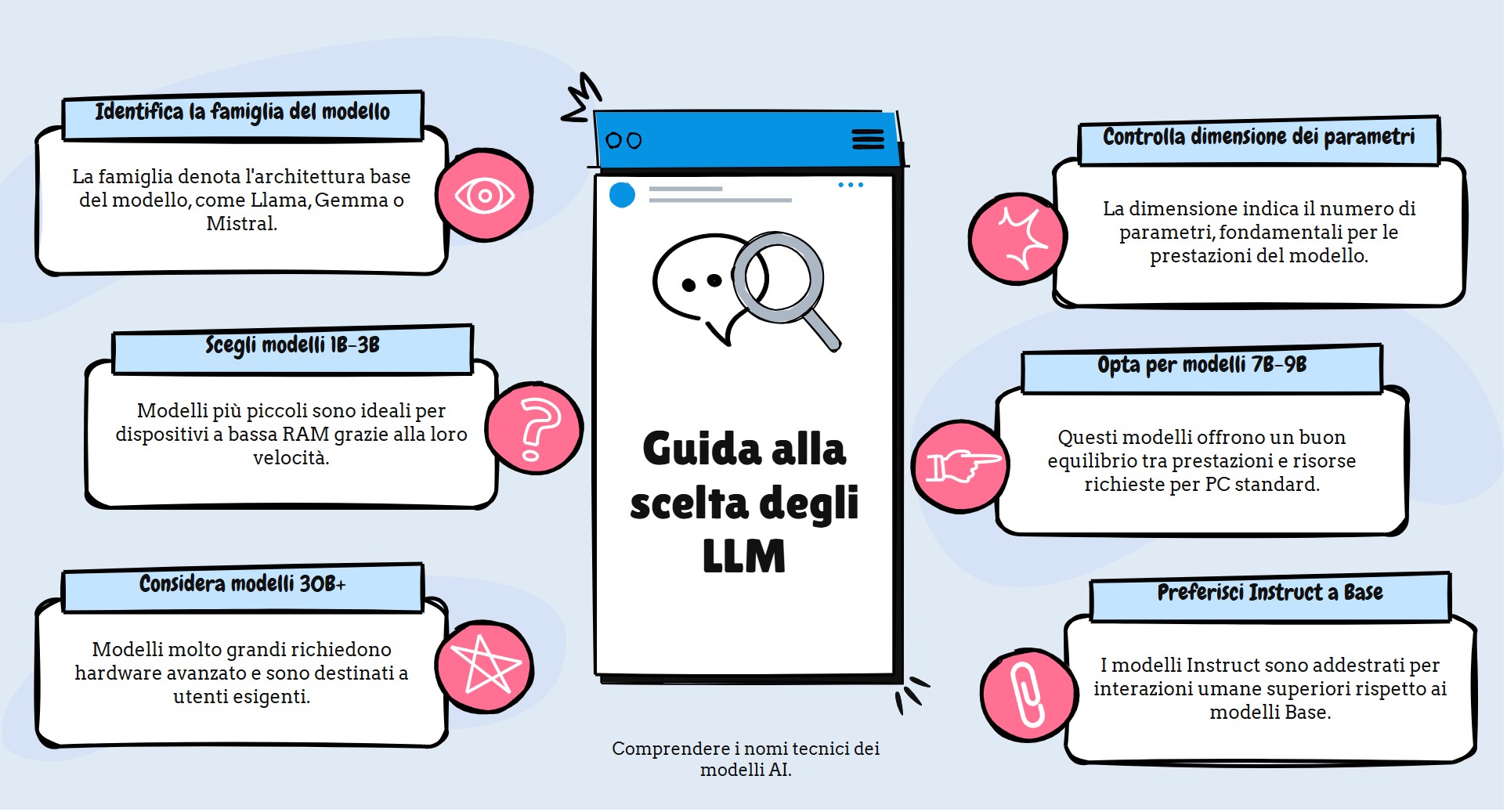 Quando cerchi un modello su Ollama, vedi nomi lunghi e strani. Capirli aiuta a non sovraccaricare la memoria del tuo dispositivo.
Quando cerchi un modello su Ollama, vedi nomi lunghi e strani. Capirli aiuta a non sovraccaricare la memoria del tuo dispositivo.
Anatomia di un nome tecnico
Esempio: Llama-3.1-8B-Instruct-Q4_K_M
Llama-3.1 (La Famiglia): mostra l’architettura. È il modello base fatto da un’azienda (qui Meta). Altre famiglie sono Gemma (Google) o Mistral.
8B (La Dimensione): vuol dire “8 miliardi di parametri”. I parametri sono le connessioni sinaptiche nella rete neurale dell’IA.
Modelli 1B-3B: veloci, adatti a dispositivi con poca RAM.
Modelli 7B-9B: bilanciati, perfetti per PC con 16 GB di RAM.
Modelli 30B+: servono hardware pro e molta VRAM.
Instruct vs Base: prendi sempre Instruct. Il modello è addestrato per parlare con le persone. I modelli Base sono per i programmatori che li modificano.
Q4_K_M (La Quantizzazione): è il trucco per l’IA locale. I modelli grandi si comprimono.
Q4 è comune: abbassa il peso senza perdere intelligenza.
La lettera alla fine (M per Medium, S per Small, L per Large) mostra quanto è forte la compressione. Q4_K_M va bene per usi normali.
L’IA locale sugli smartphone
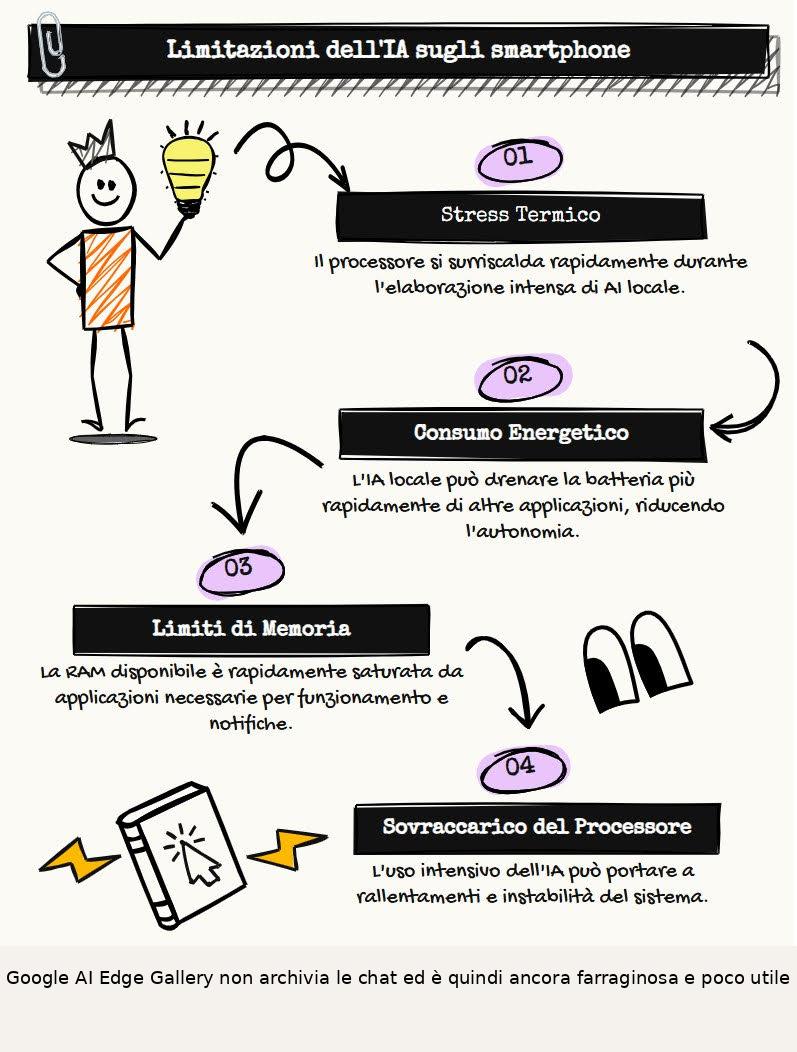 Gli smartphone moderni hanno molta potenza. Ma usare l’IA locale su di loro non è pratico.
Gli smartphone moderni hanno molta potenza. Ma usare l’IA locale su di loro non è pratico.
Ecco tre motivi:
- stress termico. Elaborare testo o immagini carica al massimo il processore. Senza ventole, il telefono si scalda in minuti. Il sistema rallenta per non rompersi;
- consumo energetico. L’IA svuota la batteria. Mezzora di chat locale toglie più carica di ore di video in HD;
- limiti di memoria. Con 12 GB di RAM, il sistema ne usa tanto per chiamate e notifiche.
Devi scegliere modelli piccoli e compressi, che sono meno furbi e precisi di quelli su PC.In sintesi: Il telefono è ottimo per chiedere a un’IA che lavora altrove. Farla lavorare “dentro” è più un trucco che una soluzione reale.
Note
[1] La RAM (Random Access Memory) è la memoria a breve termine del dispositivo. Memorizza i dati delle app in uso per un accesso rapido, essendo molto più veloce dell’archiviazione fissa su disco. È volatile, quindi si svuota allo spegnimento.
[2] Un runtime è l’ambiente software che permette a un programma (come un modello linguistico) di essere eseguito su un dispositivo.
[3] Il sito canirun.ai/ guida a capire quale configurazione sia compatibile con la propria dotazione hardware, con particolare attenzione alla quantità di RAM, destinata ad accogliere gli LLM, e alla presenza o meno di GPU (unità di elaborazione grafica), condizione necessaria per la generazione di immagini e video.
[4] Sono in cantiere anche soluzioni che uniscono le funzioni: il formato llamafile, sviluppato da Mozilla Ocho, trasforma un modello di Intelligenza Artificiale in un unico file eseguibile autosufficiente. Si tratta però di dispositivi con interfaccia minima e installazioni ancora complicate.
